Linuxは無料で使える安定した優れたOSで、いまや有料のWindowsやMac OSを駆逐する勢いです。数日前、普段利用しているUbuntu LTSのアップグレードをやってみました。Ubuntu LTSというのは、Ubuntuの長期サポート版(LTS:Long Term Supportの略で、最低5年のサポートが保障されているUbuntuバージョン)のことです。
現在私が使っているUbuntu LTS 20.04のサポート終了期限は2025年4月です。2年ぶりにリリースされた最新のLTSである「Ubuntu 22.04 LTS」は、旧版の「20.04」から大幅にバージョンアップさており、サポート終了期限は2027年4月です。今回はUbuntu 20.04 LTSを、ずっと長く安心して使えるUbuntu 22.04 LTSにアップグレードしてみました。(ちなみにUbuntu 18.04 LTSは2023年4月でサポートがきれます)
UbuntuのデスクトップはWindowsなどと同じようにマウスとキーボードで操作できるので画面をみながら、簡単にアップグレードできました。ソフトやファイルは残したままで無事アップグレードできましたが、PCの違いによってはうまくいかないことも考えられます。アップグレードする前に、念のためバックアップをとってから行うようにしましょう。
1)まず「ソフトウエアの更新」でソフトウエアを最新にします。すると、アップグレードの通知ウインドウが開きます。“このコンピュータのソフトウエアは最新です。しかしながらUbuntu 22.04.1 LTSが入手可能です(現在は20.04)”と表示され、アップグレードのボタンが表示されています。ボタンを押して、パスワードを入れて認証をするとアップグレードの手続きがはじまります。
2)新しいLTSのリリースノートが表示され、次にリリースアップグレードツールのダウンロードが始まります。いろいろメッセージがでるので確認してすすんでいくと、下の様な画面がでてアップグレード手続きが始まります。
3)次に「サードパーティーが提供するリポジトリを使わない設定にしました」というメッセージがでて、それを閉じるとこんな画面がでます。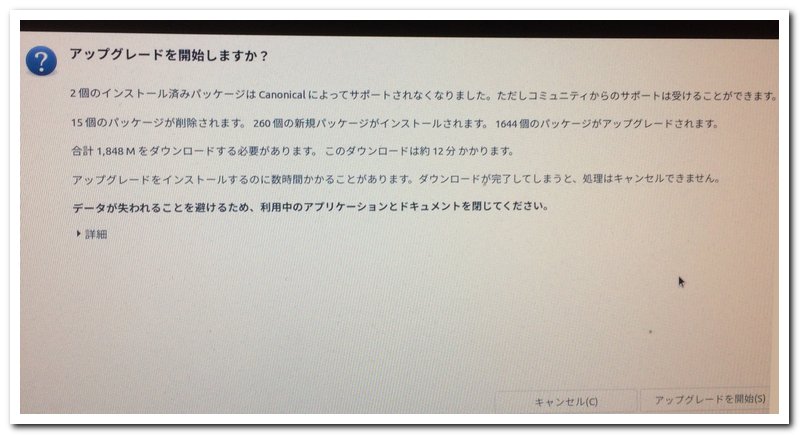
4)右下にあるアップグレードを開始のボタンを押します。するとFirefoxの設定画面がでます。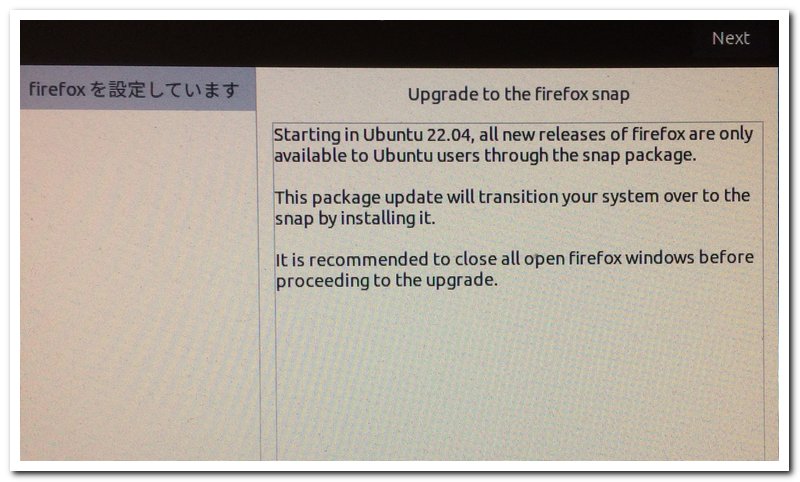 5)しばらくすると画面がすすんで次のようになります。
5)しばらくすると画面がすすんで次のようになります。

6)アップグレードのインストールがはじまり、サポートが中止された(あるいはリポジトリに存在しない)パッケージを削除しますか?と聞いてきます。>の部分をクリックして、詳細を確認して問題なければ削除してください。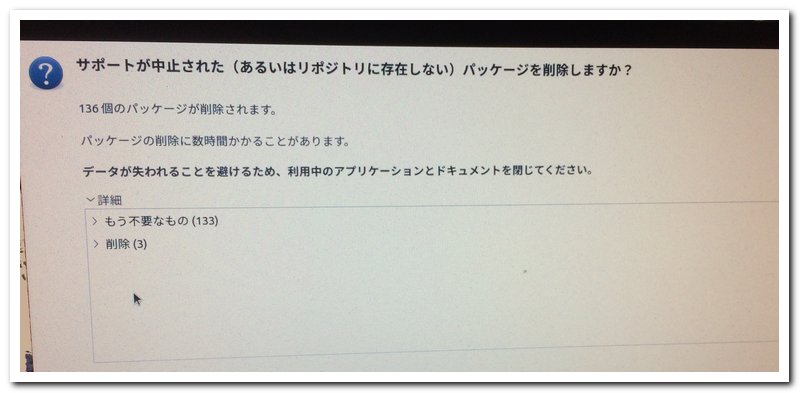

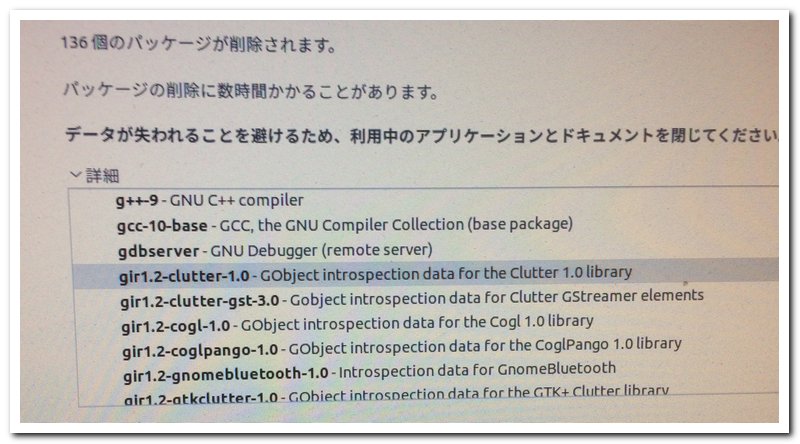
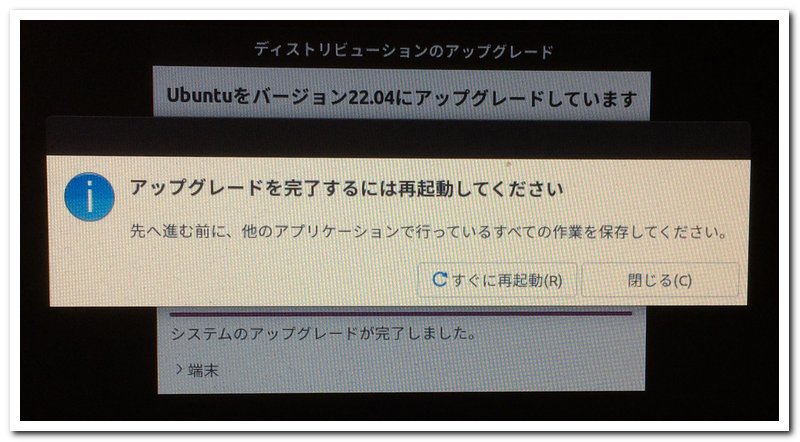
このように詳細を確認して削除して問題なければ削除します。だいたい終わるまでに1時間以上かかると思いますが何事もなくすすんで以下のようなメッセージがでたら終わりです。再起動して起動すれば完了です。今までインストールしていたソフトウエアや、存在したファイルは消えることなく残っており、ソフトウエアも問題なく使えます。
今回書いたGUIでインストールする前に、以下の記事をタブレットや別のPCで開いておくと、問題がおこったとき解決しやすいと思います。
https://tech.uzabase.com/entry/2022/10/05/163458
この記事にはFUSEをインストールするとぶっ壊れるとありましたが、今回のインストールでは対策がなされているようで、インストールしても問題ありませんでした。
 福岡はクリスマスイブ、クリスマスは極寒でした。24日の朝には自宅の屋根の波板にバネのようなつららが下がっていました。もうすこし伸びると本当のバネのようになるつららです。11年ほど前の記事に本当にバネのようになった写真がありました。ひさしぶりのバネ型つららです。春を呼ぶつららですね。
福岡はクリスマスイブ、クリスマスは極寒でした。24日の朝には自宅の屋根の波板にバネのようなつららが下がっていました。もうすこし伸びると本当のバネのようになるつららです。11年ほど前の記事に本当にバネのようになった写真がありました。ひさしぶりのバネ型つららです。春を呼ぶつららですね。