前に紹介したTextClipperのクリップツールの一つclipfileを作者の吉村隆樹さんがバージョンアップしてくださいました(2018/11/28)。前のバージョンを使っている方は新しいバージョンにしてください。ここからバージョンアップ版をダウンロードして解凍してできたclipfile.ctaファイルをtextclip7962フォルダ中に上書き保存するだけです。以前のバージョンでは保存日時の年号が正しく入らなかったのですが、今回のバージョンアップで2018がちゃんと入るようになりました。吉村さんによると典型的な2000年問題だったそうです。バージョンアップをお願いして数時間で新バージョンを作ってアップロードしてくださいました。吉村さん、どうもありがとうございました。
以下では先日紹介したTextClipperのクリップツールclipfileの使い方をもうすこし詳しく紹介しておきます。
1)まずTextClipperをここからダウンロードしてダウンロードしたzipファイルを解凍してください。解凍してできたフォルダがtextclip7962という名前になります。このフォルダはProgram Filesのフォルダには入れないでください。入れると動きません。このプログラムを使用するには7-zip32.dllが必要です(バックアップ時)のでここから取得してください。
2)ここまでの作業でtextclip7962というフォルダができました。バージョン番号がフォルダ名になっていますね。TextClipper本体はこのフォルダの中にあるtextclip.exeです。これをダブルクリックするとTextClipperが起動します。このソフトの使い方については
http://www.hi-ho.ne.jp/makoto_watanabe/tc/index.html などをみてください。
では次にclipfileというクリップツール(TextClipperの機能拡張のようなものです)をインストールしましょう。これはブラウザにかぎらずMS WordやAcrobat Readerで表示しているpdfファイルなど、任意のソフトで表示しているテキストを選択し、それを規定の名前のテキストファイルTc_txt.txtに次々と保存できるツールです。
一つのテキストファイルに、保存日時と出典、および保存時に追加できる任意のキーワードとともに保存してくれます。新しくクリップしたテキストはもとのテキストファイルの末尾に追加されます。これを使うと、ネットサーフィンで見つけたテキストをキーワード付きでテキストファイルで保存できますので、あとで秀丸など適当なテキストエディタでgrep検索して簡単に探し出すことができます。保存するときに将来検索の時に思いつきそうな、「選択したテキストには含まれないキーワード」を追加しておけるので、後々の検索時に探しもれが少なくなるのもこのツールの便利な点です。
3)では、clipfileを使えるようにしましょう。
以下のurlからクリップツールのclipfileを選んでダウンロードします。
http://takaki.la.coocan.jp/freesoft/textclipper/
ここをクリックしてダウンロードしてもいいと思います。clipfile.zipがダウンロードできますので、前に紹介した7-Zipなどのソフトで解凍します。解凍してできたclipfile.ctaというファイルを上の2)でできたtextclip7962のフォルダにドラッグして移動させます。これでclipfileを使う準備ができました。
4)TextClipperを起動して、clipfileを使ってみましょう。
まずTextClipperを起動します。
上の図のヘルプの左にある、環境設定を選び、
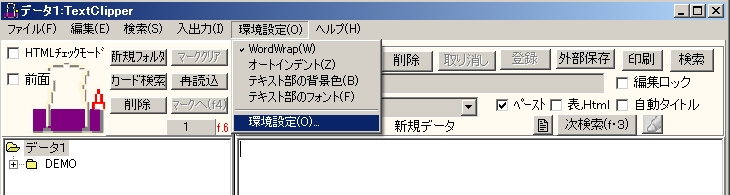
開いてでてくるメニューでクリップツールキーをAlt+cなど好きなキーの組み合わせに設定します。
これでAlt+Cを押したらクリップツールが動くように設定できました。
5)では、実際にテキストを適当に選んでスクラップブックのようにテキストファイルに保存してみましょう。
まずTextClipperを起動しておいてください。そのあと、ブラウザなどで適当なサイトを訪れて、保存したいテキストを選択し、さっき決めておいたクリップツールキー(Altをおして同時にCを押す)を押します。すると下の画像のようにポップアップメニューが開いて一番上に「TextFileに追加」がありますのでこれを選択します。
 するとキーワード入力のポップアップ画面が開きますので、あとで検索に便利なキーワードを入れます。複数入れても構いません。自由に入力しましょう。
するとキーワード入力のポップアップ画面が開きますので、あとで検索に便利なキーワードを入れます。複数入れても構いません。自由に入力しましょう。
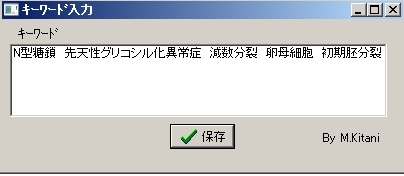
保存ボタンをおして完了です。Tc_text.textという名前のファイルに上の選択した部分が出典の一部、日時、キーワードとともに保存されているはずです。
ではうまく保存できたかどうかをtextclip7962フォルダ内にできているTc_txt.textというファイルを開いて確認しましょう。出典、日付、キーワード、クリップしたテキストの順に保存されていたら成功です(下図参照)。

上の例では、私の去年の学会でのランチョンセミナーの講演動画がでているYouTubeのページにあるテキストをクリップしたテキストの後に、今しがたクリップした論文のテキストが追加されています。N型糖鎖、先天性グリコシル化異常症などとあるのは、さきほどつけたキーワードです。その下にクリップしたテキストが保存されているのがわかります。
このように、ちょっと気になったテキストを、どんどんクリップして蓄積しておき、あとで秀丸エディタなどのテキストエディタのgrep検索機能で検索します。grep機能についているタグジャンプ機能を使えば該当するクリップしたテキスト全文のある場所に容易にジャンプすることができます。テキストファイルのサイズが大きくなってきたら、Tc_text.textファイルの名称をTc_text1.txtなどすきな名前に変更します。次にclipfileツールでクリップしたら、自動的にまっさらなTc_txt.txtファイルができてそこに保存されますので、またゼロからクリップがはじめられます。
こうしてできた大量のクリップファイルを一斉に grep検索したら何年にもわたって蓄積したデータを一瞬で検索できて便利です。データはテキストファイルですので、加工も活用もきわめて簡単です。英語論文の例文集の作成、アイデアメモの作成などいろいろな用途につかえるすばらしいツールですので是非活用してみてください。
写真は福岡で撮影したイチョウです。とてもきれいに黄葉しています。秋も深まってきました。
