前回紹介した英語論文用の例文集に使えるAntConcはテキストファイルやhtmlファイルを扱いますが、最も身近な英語の例文集の素材はpdfファイルだと思います。そこで今回は英語の例文集の作成のために重宝する、「pdfファイルをテキストファイルに変換する方法」を紹介します。AcrobatやFoxit Readerなどでpdfを開いて、textファイルとして保存する方法は、pdfファイルが数百、数千ある場合は手作業では対応できません。こんな場合は、Acrobatなどで複数のpdfファイルを一つのpdfファイルに結合してからtextファイルに変換するという方法もありますが、そんなめんどうくさいことをしなくてもpdftotextという無料ソフトを使えば一括で複数のpdfファイルをそれぞれ別のテキストファイルに変換でますので、やってみましょう。
まずpopplerというpdfを扱うプログラミングライブラリ(その中にpdftotextが入っています)をお使いのWindows, Mac, linux用のものを選んでダウンロードしてインストールします。linuxではsudoコマンドでpopplerをダウンロードしてインストールできますし、Mac版もアプリストアからダウンロードできるはずです。私が使っているWindows 10やWindows 7のPCの場合については、ここに詳しいインストールの仕方が書いた記事がでているのを見つけました。大変丁寧に書いてありますのでそのよく読んでインストールしてください。私もこの記事のとおりにインストールして利用しています。
私はCドライブ直下にpoppler-0.68.0というフォルダ(ダウンロードしたPopplerの圧縮ファイルを解凍(解凍ソフトは註1をみてください)してできるフォルダ名のままコピーしただけです)を作り、その直下にあるbinフォルダ(binaryフォルダの意味で、実行ファイルが入っているフォルダのことです)に自分の必要なpdfファイルを集めてテキストファイルに変換しています。shareフォルダの下にはpopplerとrenameしたデータファイル(上述のホームページにあるリンク
https://poppler.freedesktop.org/poppler-data-0.4.9.tar.gz からダウンロードしたpoppler-data-0.4.9.tar.gzファイルを解凍したもの。註1参照)をおいてください。あとは以下のコマンドを記述したバッチファイルをテキストファイルエディタで作ることが必要です。
for %%i in (*.pdf) do (pdftotext %%i %%i.txt)
このコマンドをテキストファイルエディタにうちこみ、できたファイルに適当な名前(pdf2txt.batとかすきな名前)をつけて保存します。保存のときデフォルトではテキストファイルで保存されれウため、pdf2txt.txtになりますのでファイル名の変更でpdf2txt.batにするか、保存時に.batで保存してください。保存場所はpdftotextのあるフォルダ(上の例ではbinフォルダ)にします。
あとは、変換したいpdfファイルを上のbinフォルダにコピーして、コマンドプロンプトでpdf2txt.batファイルを実行するだけです。日本語のファイルも英語のファイルもともにテキストファイルに変換されます。(invalid font weightというエラーが出るかもしれませんが無視してよいようです。不都合があったら教えてください。)
以下はコマンドプロンプトが初めての人むけの簡単な説明です(註2参照)。
バッチファイルというのはwindowsのコマンドプロンプト(windows7では「すべてのプログラム」の部分をみていくと、アクセサリフォルダの下にあります。windows10では下の図の左端の写真ようにシステムツールの下にあります。)でファイル名を入力してエンターを押すと、ファイル内に書いてあるコマンドを逐次実行するというものです。
矢印のコマンドプロンプトをクリックして起動するとき右クリックで、管理者として実行を選んで起動しておくと管理者としてログインしていないときにおこるトラブルをさけられますので注意してください。
今回のバッチファイルは以下のような内容で動きました。
for %%i in (*.pdf) do (pdftotext %%i %%i.txt)
意味は、iという変数にpdfのファイル名をいれ、それにpdftotextコマンドを実行してpdfのファイル名(%%i)のついたテキストファイル(%%i,txt)を作るという操作をフォルダ内にあるすべてのpdfファイル(*.pdfというワイルドカード*を使っている部分で、任意のファイル名のpdfファイルを表しています) がなくなるまで一個ずつ繰り返す(for doの部分)というものです。
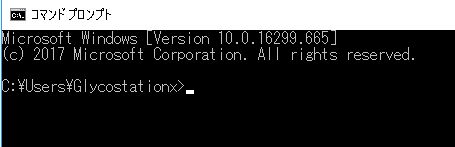
コマンドプロンプトを上に説明したように起動すると、黒いバックに白い字の画面が開きます(上の真ん中の図)
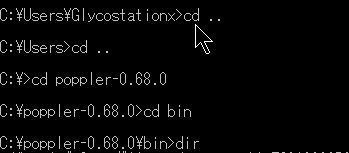
自分の今いるディレクトリ(フォルダ)の名前が表示されています。これから目的のpopplerのフォルダを探すとき、たとえばCドライブの直下にpopplerのフォルダがあるなら、コマンドプロンプトでcd ..(cdとうって、ピリオドを二回うちます)というコマンド(これはディレクトリを上に登って行くコマンドです)を何回かうってディレクトリをC:¥>にします。上の図の右端の図。
dirとうつとディレクトリやファイルの一覧が表示されます。
popplerのフォルダへ移りたいのでcd poppくらいまでをタイプしてあとはタブキーを押してください。タブの自動補完機能でcd poppler-0.68.0と自動入力されます。(このタブ補完の機能はlinuxで重宝するのですがWindowsのコマンドプロンプトでも利用できますので活用してください。) enterキーを押すとC:¥poppler-0.68.0>と表示されてディレクトリを移動したのがわかります。ここでdirとうってenterを押すとディレクトリ内のファイルとフォルダが表示されます。プログラムファイルのあるbinのフォルダ(ディレクトリ)があるのを確認してください。cd binとうってenterを押すとbinのディレクトリに移動します。C:¥poppler-0.68.0\binとなっていたら成功です(上の右端の図)。再びdirとうってenterをおします。これでこのbinフォルダ内にあるすべてのファイルとフォルダが表示されます。あとはそこにコピーしてあるバッチファイルpdf2txt.batを実行する(コマンドラインにpdf2txtとうってenterを押す)と、自動的にファイル名のついたtxtファイルができあがります。
こうして一括でpdfファイルをテキストファイルに変換したら、あとはこれらのテキストファイルをAntConcに読み込んでコーパスとして論文を書くときに参照すればいいわけです。
もちろんテキストファイルですから、テキストファイルを一括検索して、検索結果にタグジャンプして参照できるgrepコマンドも使えます。適当な、grepコマンドが使えるエディタ(たとえば有料ですが秀逸なエディタでおすすめの秀丸エディタ)でpdfの内容を串刺し検索するのもよいですね。pdfgrepというソフトもあって、これを使えばpdfファイルのままでgrepができるそうです。これはまだ使っていません。windows版をダウンロードしてさきほどのbinファイルにコピーしておけば、コマンドプロンプトで使えるのですが、linux版とちがって検索語がハイライトしなかったりしてまだ使いこなせていません。興味のある方は使ってみてください。
註1:圧縮ファイルの解凍には私は7-zipを使っています。たいていの圧縮解凍はこれでできます。
註2:パスの通し方とかは説明しないでpdftotextを使う方法を説明していますので、良く知っている方はパスを通して適当な場所にpdftotextをおいて使ってください。